
https://arxiv.org/abs/2401.02326
Introduction
まず、Segment Anything Modelという画像が与えられたときに、テキストなどの入力で所定のものをセグメントできるようなすごい基盤モデルがある。
論文: https://segment-anything.com/
機能としていろいろできるが、例えば、イラストの点を打つだけで、セグメントしてる区域を限定できる。
だが、SAMはレーダーで撮影している画像に対してはうまくいかない問題がある。

Method
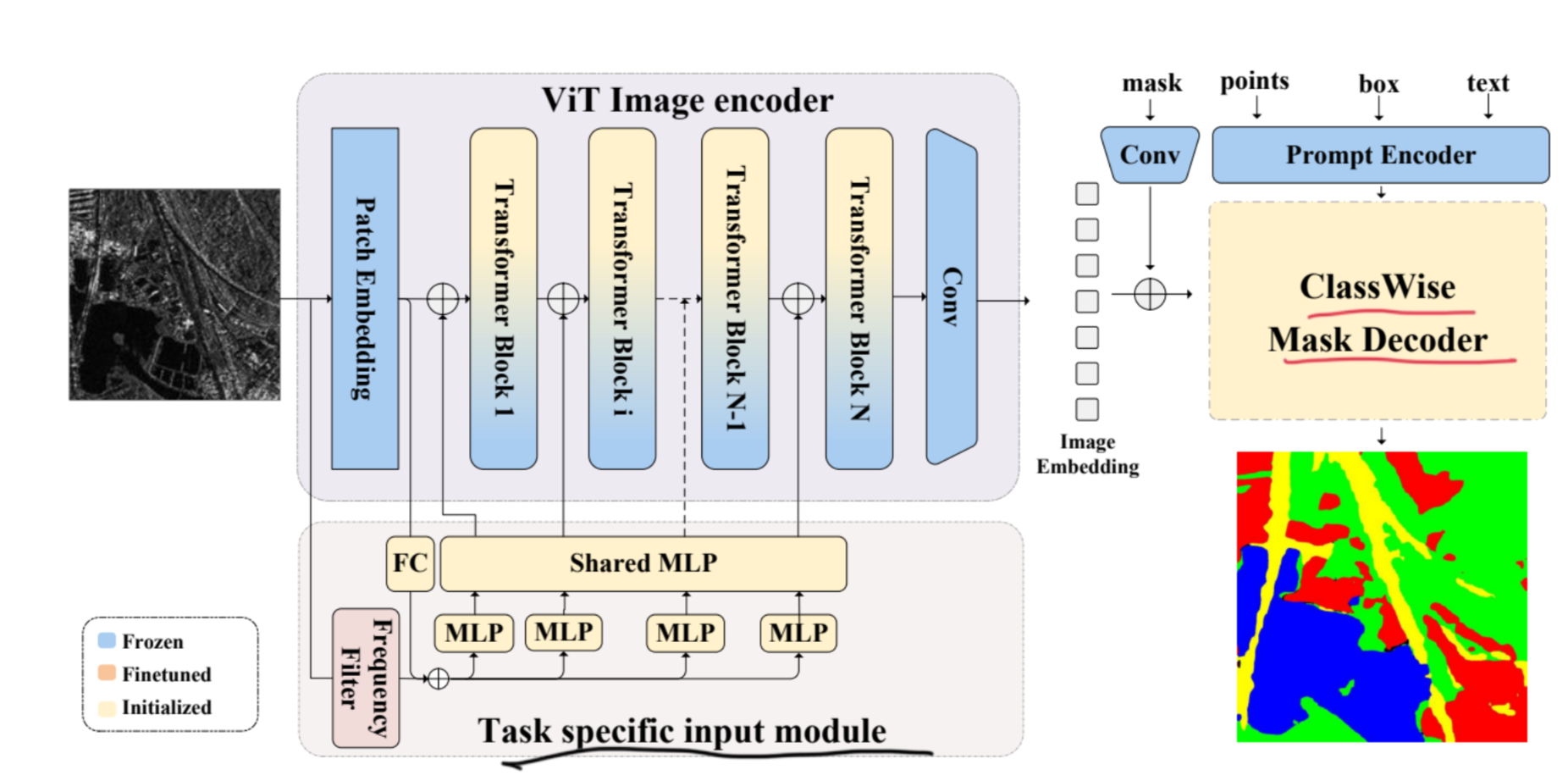
まずは画像にVision Transformerを適用させて、Image Embeddingを作る。
Transformer Block
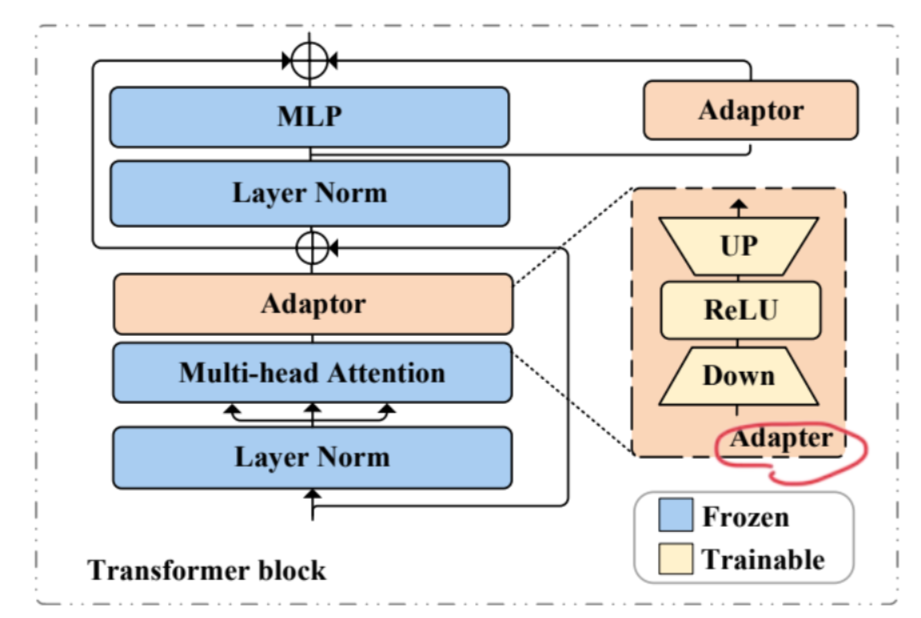
Vision Transformerの部分では、Transformerに関係する部分は以上のようになっている。これはSAMのVision Transformerのアーキテクチャであり、重みをそのままロードしたものをFrozenさせている。
Adapterでは、次元をいったん落として重要な特徴量を保存させる意図がある。DownとUPは全結合層で線形なので、中にReLUの活性化関数を入れて非線形性を与えている。
全体としては、残差接続などで6通りあるが、新たに追加したのはAdaptor関連のものだけ。
- Multi-head Attention → Adaptorはたぶん高すぎたMulti-head Attentionの表現力をAdaptorで絞っている。
Class-wise Mask Decoder
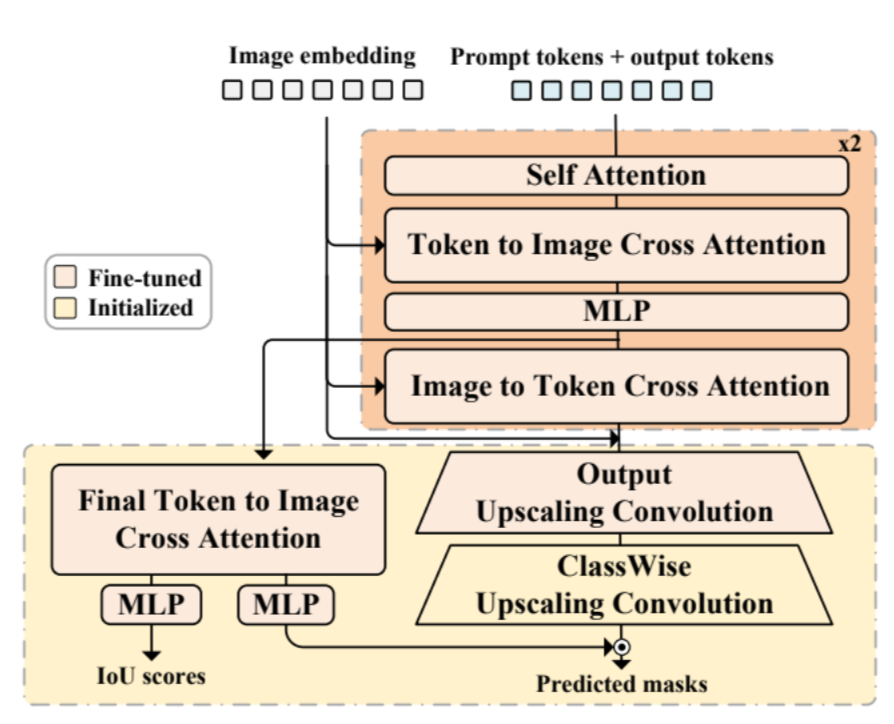
Multimodalを実現している部分。Image EmbeddingとPrombt Embeddingを与えられる。このユニットでは最終的な出力を作っている。
まず、以下のものを2セット繰り返す。
- PromptについてSelf Attentionをする。
- そこにImage Embeddingを入れて、TokenからImageへのCross Attentionを行う(ImageをAttentionして得ている)。
- MLPを通す。
- 再度Image Embeddingを入れて、今度はImageからTokenへのCross Attentionを行う。
- 前にToken to ImageでImageをAttentionしているので、再度ImageからTokenにしてTokenをAttentionしている。
Imageのほうが大事なので最後に、2セット繰り返した後Image Embeddingをさらに残差接続させる。
予測のマスクについて、Upscaling Convolutionを行う。これは、deconvolution()という当初のチャンネル以上の数のチャンネルに作り上げる逆畳み込みをする。
なお、Output Upscaling ConvolutionはSAMにあるモジュールで、なんでもセグメントしてしまう。その一方Class-wise Upscaling Convolutionは、限定のクラス(与えたPromptに従ったもの)に限定したものをセグメンテーションをしたいという役割をはたしている。
Final Token to Image Cross Attentionは、単純に途中抜けしているので、Token to Image Cross Attentionをやっている。
Frequency Filter
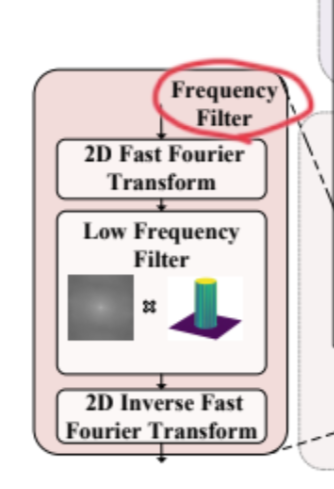
Frequency Filterは数理的に、ノイズ除去をしている。
FFTをして高周波数成分をノイズとして取り除き、逆FFTをしている。